【MySQL】十四、深入MySQL索引的秘密(二)
本文主要介绍MySQL数据库的必须要掌握的索引的相关知识
更新数据的时候,自动维护的聚簇索引到底是什么
现在假设我们要搜索一个主键id对应的行,此时你就应该先去顶层的索引页88里去找,通过二分查找的方式,很容易就定位到你应该去下层哪个索引页里继续找,如下图所示
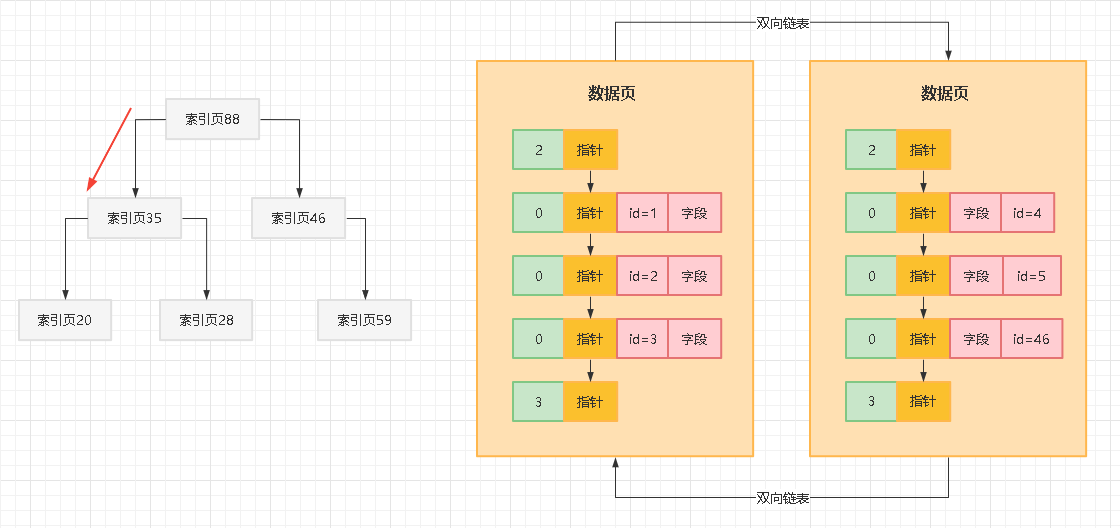
比如现在定位到了下层的索引页35里去继续找,此时在索引页35里也有一些索引条目的,分别都是下层各个索引页(20,28,59)和他们里面最小的主键值,此时在索引页35的索引条目里继续二分查找,很容易就定位到,应该再到下层的哪个索引页里去继续找,如下图所示:
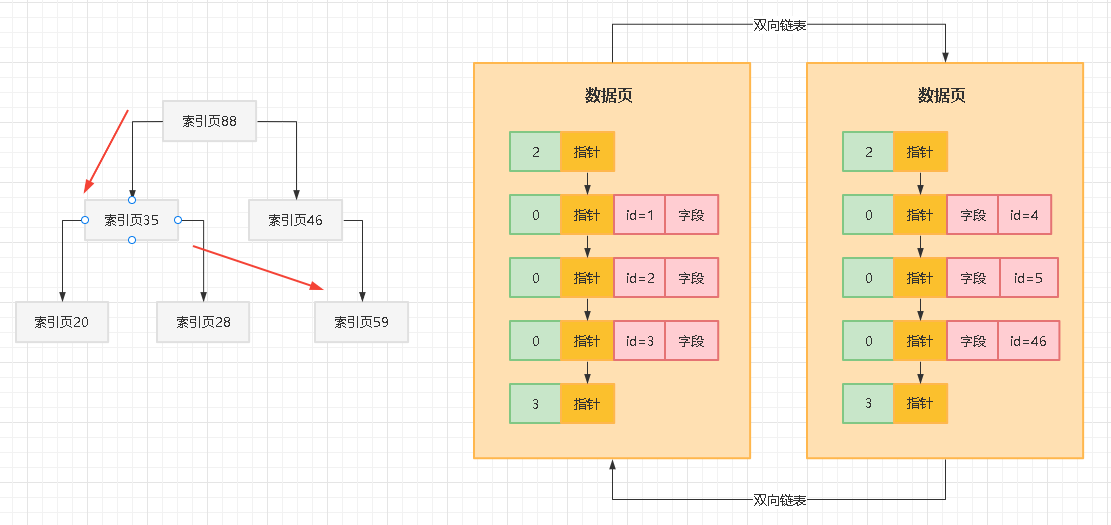
我们这里看到,可能从索引页35接着就找到下层的索引页59里去了,此时索引页59里肯定也是有索引条目的,这里就存放了部分数据页页号(比如数据页2和数据页8)和每个数据页里最小的主键值
此时就在这里继续二分查找,就可以定位到应该到哪个数据页里去找,如下图所示:
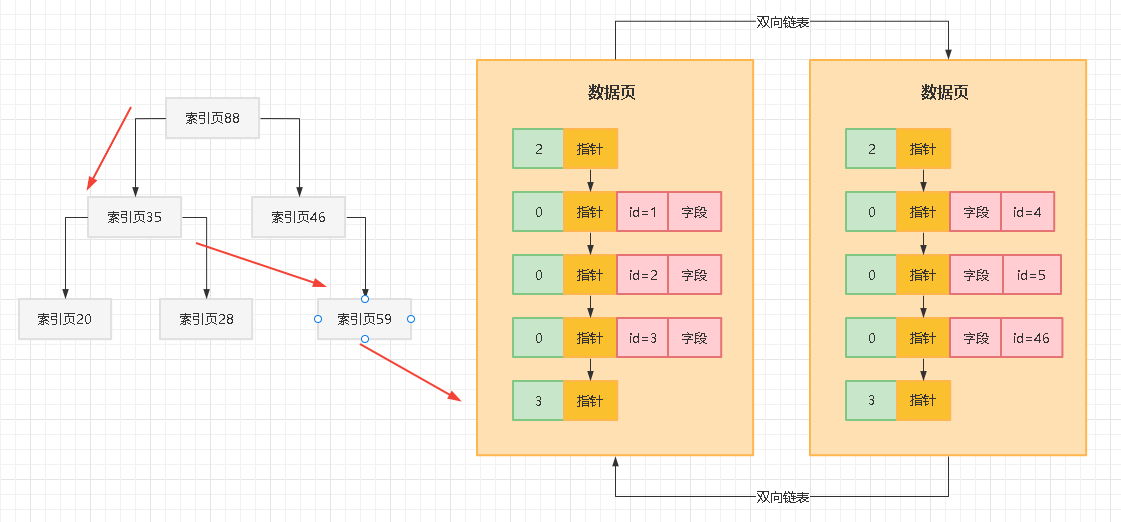
接着比如进入了数据页2,里面就有一个页目录,都存放了各行数据的主键值和行的实际物理位置。
此时在这里直接二分查找,就可以快速定位到你要搜索的主键值对应行的物理位置,然后直接在数据页2里找到那条数据即可了。
这就是基于索引数据结构去查找主键的一个过程,那么大家有没有发现一件事情,其实最下层的索引页,都是会有指针引用数据页的,所以实际上索引页之间跟数据页之间是有指针连接起来的,如下图:
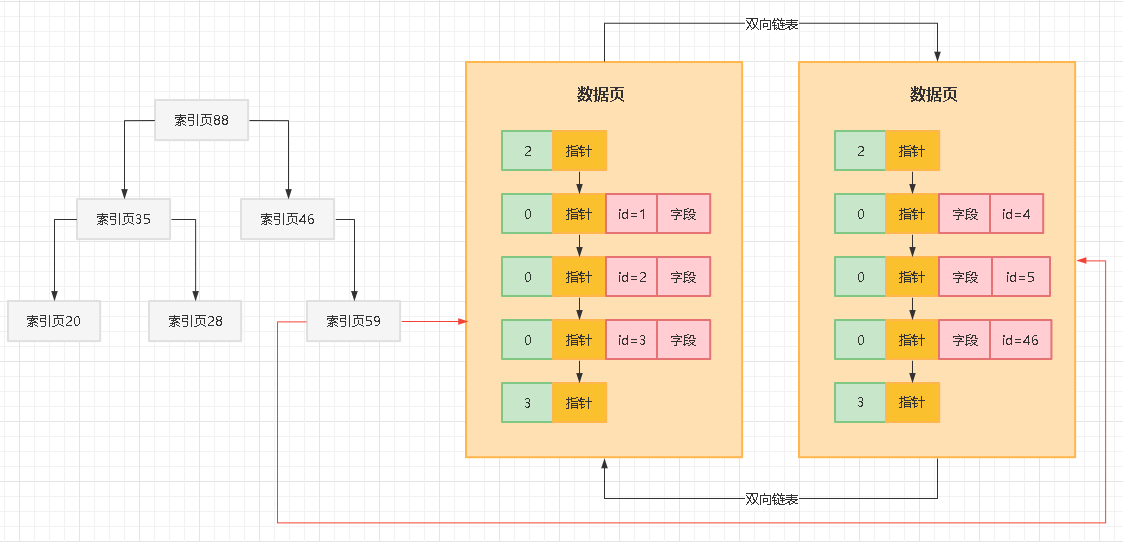
另外,其实索引页自己内部,对于一个层级内的索引页,互相之间都是基于指针组成双向链表的,如下图所示:
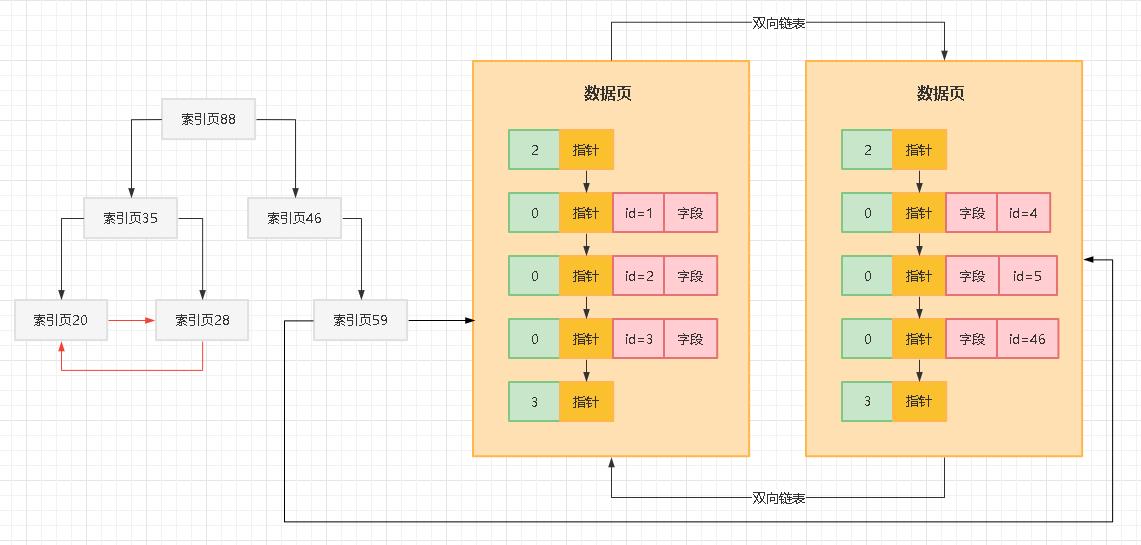
把上面的图连起来看,就是说假设把索引页和数据页综合起来看,他们都是连接在一起的,看起来就如同一个完整的大的B+树一样,从根索引页88开始,一直到所有的数据页,其实组成了一颗巨大的B+树。
在这颗B+树里,最底层的一层就是数据页,数据页也就是B+树里的叶子节点了。
所以,如果一颗大的B+树索引数据结构里,叶子节点就是数据页自己本身,那么此时我们就可以成这颗B+树索引为聚簇索引。
也就是说,上图中所有的索引页+数据页组成的B+树就是聚簇索引。
其实在InnoDB存储引擎里,你在对数据增删改的时候,就是直接把你的数据页放在聚簇索引里的,数据就在聚簇索引里,聚簇索引就包含了数据,比如你插入数据,那么就是在数据页里插入数据。
如果你的数据页开始进行页分裂了,他此时会调整各个数据页内部的行数据,保证数据页内的主键值都是有顺序的,下一个数据页的所有主键值大于上一个数据页的所有主键值。
同时在页分裂的时候,会维护你的上层索引数据结构,在上层索引页里维护你的索引条目,不同的数据页和最小主键值。
然后你的数据页越来越多,一个索引页放不下了,此时就会再拉出新的索引页,同时再搞一个上层的索引页,上层索引页里存放的索引条目就是下层索引页页号和最小主键值。
按照这个顺序,以此类推,如果你的数据量越大,此时可能就会多出更多的索引页层级来,不过说实话,一般索引页里可以放很多索引条目,所以通常而言,即使你是亿级的大表,基本上大表里建的索引的层级也就三四层而已。
这个聚簇索引默认是按照主键来组织的,所以你在增删改数据的时候,一方面会更新数据页,一方面其实会给你自动维护B+树结构的聚簇索引,给新增和更新索引页,这个聚簇索引是默认就会给你建立的。
针对主键之外的字段建立的二级索引是如何运作的
假设你要针对其他字段建立索引,比如name、age之类的字段,这都是一样的原理,简单来说,比如你插入数据的时候,一方面会把完整数据插入到聚簇索引的叶子节点的数据页里去,同时维护好聚簇索引,另一方面会为你其他字段建立的索引,重新再建立一颗B+树。
比如你基于name字段建立了一个索引,那么此时你插入数据的时候,就会重新搞一颗B+树,B+树的叶子节点也是数据页,但是这个数据页里仅仅放主键字段和name字段,大家看下面的示意图:
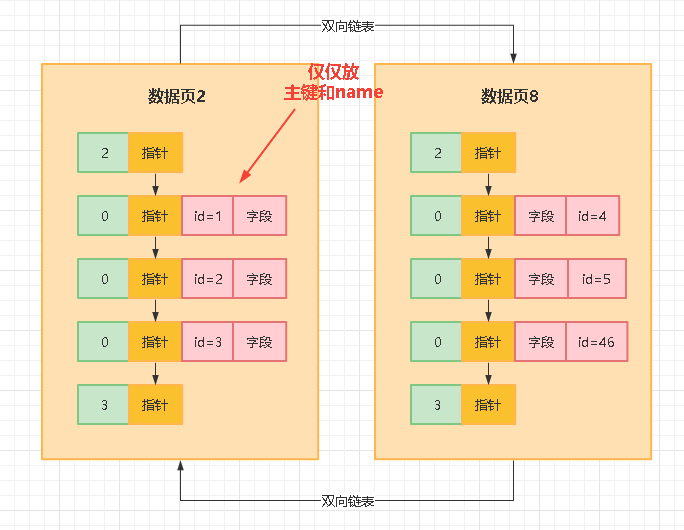
大家注意,这可是独立于聚簇索引之外的另外一个所以B+树了,严格来说是name字段的索引B+树,所以在name字段的索引B+树里,叶子节点的数据页里仅仅放主键和name字段的值,至于排序规则之类的,都是和之前说的一样的。
也就是说,name字段的索引B+树里,叶子节点的数据页中的name值都是按大小排序的,同时下一个数据页里的name字段值都大于上一个数据页里的name字段值,这个整体的排序规则都跟聚簇索引按照主键的排序规则是一样的。
然后呢,name字段的索引B+树也会构建多层级的索引页,这个索引页里存放的就是下一层的页号和最小name字段值,整体规则都是一样的,只不过存放的都是name字段的值,根据name字段值排序罢了。
所以假设你要根据name字段来搜索数据,那搜索过程简直都一样了,不就是从name字段的索引B+树里的根节点开始找,一层一层往下找,一直找到叶子节点的数据页里,定位到name字段值对应的主键值。
然后呢,此时针对 select * from table where name = ‘xx’这样的语句,你先根据name字段值在name字段的索引B+树里找,找到叶子节点页仅仅可以找到对应的主键值,而找不到这行数据完整的所有字段。
所以此时还需要进行”回表”,这个回表就是说还需要根据主键值,再到聚簇索引里从根节点开始,一路找到叶子节点的数据页,定位到主键对应的完整数据行,此时才能把select *要的全部字段值都拿出来。
因为我们根据name字段的索引B+树找到主键之后,还要根据主键去聚簇索引里找,所以一般把name字段这种普通字段的索引称之为二级索引,一级索引就是聚簇索引,这就是普通字段的索引的运行原理。
其实我们也可以把多个字段联合起来,建立联合索引,比如name+age
此时联合索引的运行原理也是一样的,只不过是建立一颗独立的B+树,叶子节点的数据页里放了id+name+age,然后默认按照name排序,name一样就按照age排序,不同数据页之间的name+age值的排序也如此。
以上就是innodb存储引擎的索引的完整实现原理了。
插入数据时到底如何维护好不同索引的B+树的?
首先呢,其实刚开始你一个表搞出来以后,其实他就一个数据页,这个数据页就是属于聚簇索引的一部分,而且目前还是空的,此时如果你插入数据,就是直接在这个数据页里插入就可以了,页没必要给他弄什么索引页。
然后呢,这个初始的数据页其实就是一个根页,每个数据页内部默认就有一个基于主键的页目录,所以此时你根据主键来搜索都是ok没问题的,直接在唯一一个数据页里根据页目录找就行了。
然后表里的数据越来越多了,此时你的数据页满了,那么就会搞一个新的数据页,然后把你根页面里的数据都拷贝过去,同时再搞一个新的数据页,根据你的主键值的大小进行挪动,让两个新的数据页根据主键值排序,第二个数据页的主键值都大于第一个数据页的主键值。
那么此时那个根页在哪呢?此时根页就升级为索引页了,这个根页里放的是两个数据页的页号和他们里面最小的主键值。
接着肯定还是会不停的在表里面灌入数据,然后数据页不停的页分裂,分裂出来越来越多的数据页,此时你的唯一一个索引页,也就是根页里存放的数据页索引条目越来越多,连你的索引页都放不下了,那你就让一个索引页分裂成两个索引页,然后根页继续往上周一个层级引用了两个索引页。
接着就是以此类推了,你的数据页越来越多,那么根页指向的索引页页会不停分裂,分裂出更多的索引页,当你下层的索引页数量太多的时候,会导致你的根页指向的索引页太多了,此时根页继续分裂成多个索引页,根页再次往上提上去一个层级。
这其实就是你增删改的时候,整个聚簇索引维护的一个过程,其实其他的二级索引也是类似的一个原理
比如你name字段有一个索引,那么刚开始的时候你插入数据,一方面在聚簇索引的唯一的数据页里插入,一方面在name字段的索引B+树唯一的数据页里插入。
然后后续数据越来越多了,你的name字段的索引B+树里唯一的数据页也会分裂,整个分裂的过程跟上面说的是一样的,所以你插入数据的时候,本身就会自动去维护你的各个索引的B+树。
另外,你的name字段的索引B+树里的索引页中,其实除了存放页号和最小name字段值以外,
看看几个最常见和最基本的索引使用规则
等值匹配,就是你where语句中的几个字段名称和联合索引的字段完全一样,而且都是基于等号的等值匹配,那百分百会用上我们的索引,即使你where语句里写的字段的顺序和联合索引里的字段顺序不一致也没关系,MySQL会自动优化为按联合索引的字段顺序去找。
最左侧列匹配,这个意思就是假设我们联合索引是KEY(class_name, student_name,subject_name),那么不一定必须要在where语句里根据三个字段来查,其实只要根据最左侧的部分字段来查,也是可以的。
比如你可以写select * from student_score where class_name=’’ and subject_name=’’,就查某个学生所有科目的成绩,这都是没问题的。
但是假设你写了一个select * from student_score where subject_name = ‘’,那就不行了,因为联合索引的B+树里,是必须先按class_name查,再按student_name查,不能跳过前面两个字段,直接按最后一个subject_name查的。
另外,假设你写一个select * from student_score where class_name=’’ and subject_name=’’,那么只有class_name的值可以在索引里搜索,剩下的subject_name是没法再索引里查找的。
最左前缀匹配原则,即如果你要用like语法来查,比如select * from student_score where class_name like ‘1%’,查找所有1大头的班级的分数,那么也是可以用到索引的。
范围查找规则,意思是我们可以用select * from student_score where class_name > ‘1班’ and class_name < ‘5班’ 这样的语句来范围查找某几个班级的分数。这个时候也会用到索引的。
但是如果你要是写select * from student_score where class_name > ‘1班’ and class_name <’5班’ and student_name > ‘’,这里只有class_name是可以基于索引来找的,student_name的范围查询是没办法用到索引的。
等值匹配+范围匹配的规则,如果你要是用select * from student_score where class_name = ‘1班’ and student_name > ‘’ and subject_name < ‘’,那么此时你首先可以用class_name在索引里精确定位到一波数据,接着这波数据里的student_name都是按照顺序排列的,所以student_name >‘’也会基于索引来查找,但是接下来的subject_name< ‘’是不能用索引的。
【MySQL】十四、深入MySQL索引的秘密(二)