【MySQL】八、MySQL的事务(二)
本文主要介绍MySQL数据库的事务
7.5 SQL标准中对事务的4个隔离级别都是如何规定的
数据库中多个事务并发时可能产生的问题包括脏写、脏读、不可重复读、幻读几个问题,那么针对这些多事务并发的问题,实际上SQL标准中就规定了事务的集中隔离级别,用来解决这些问题。
在SQL标准中规定了4中事务隔离级别,就是说多个事务并发运行的时候,相互是如何隔离的,从而避免一些事务并发问题。
这四种级别包括了:read uncommitted(读未提交)、read committed(读已提交)、repeatable read(可重复读)、serializable(串行化)
不同的隔离级别是可以避免不同的事务并发问题的
read uncommitted 隔离级别是不允许发生脏写的;也就是说不可能两个事务在没提交的情况下去更新同一行数据的值,但是在这种隔离级别下,可能发生脏读,不可重复读,幻读。
read committed 隔离级别是不会发生脏写和脏读,也就是说人家事务没提交的情况下修改的值,你是绝对读不到的,但是呢,可能会发生不可重复读和幻读问题,因为一旦人家事务修改了值然后提交了,你事务是会读到的,所以可能你多次读取到的值是不同的。
repeatable read 隔离级别就是可重复读,在这个级别下,不会发生脏写、脏读和不可重复读的问题,因为你一个事务多次查询一个数据的值,哪怕别的事务修改了这个值还提交了,你也不会读取到人家提交事务修改过的值,你事务一旦开始,多次查询一个值,会一直读到同一个值。
但是repeatable read隔离级别还是会发生幻读的,因为假设你一次SQL是根据条件查询,第一次查询出10条数据,结果另外一个事务插入了一条数据,下次你可能会查出来11条数据,还是会有幻读的问题。repeatable read隔离级别只不过保证对同一行数据的多次查询,你不会读到不一样的值,人家已提交事务修改了这行数据的值,对你也没影响。
serializable隔离级别,这种级别根本不允许你多个事务并发执行, 只能串行起来执行,先执行事务A提交,然后执行事务B提交,接着执行事务C提交,所以此时根本不可能有幻读的问题,因为事务压根儿都不并发执行。这种隔离级别一般不会使用,因为多个事务串行,数据库性能会非常差。
7.6 MySQL是如何支持4中事务隔离级别的?
MySQL默认设置的事务隔离级别,都是RR级别的,而且MySQL的RR级别是可以避免幻读发生的,这点是MySQL的RR级别的语义跟SQL标准的RR级别不同的,毕竟SQL标准里规定RR级别是可以发生幻读的,但是MySQL的RR级别避免了。
也就是说,MySQL里执行的事务,默认情况下不会发生脏写、脏读、不可重复读和幻读的问题,事务的执行都是并行的,大家互相不会影响,我不会读到你没提交事务修改的值,即使你修改了值还提交了,我也不会读到的,即使你插入了一行值还提交了,我也不会读到的。总之,事务之间互相都完全不影响。
假设要修改MySQL的默认事务隔离级别,是下面的命令,可以设置级别为不同的level,level的值可以是REPEATABLE READ,READ COMMITTED, READ UNCOMMITTED, SERIALIZABLE几种级别。
1 | SET [GLOBAL|SESSION] TRANSACTION ISOLATION LEVEL level; |
但是一般来说,其实不用修改这个级别,就用默认的RR其实就特别好,保证你每个事务跑的时候都没人干扰。
另外,假设你在开发业务系统的时候,比如用Spring里的@Transactional注解来做事务这块,假设某个事务就是想设置成RC级别,那么@Transactional注解里有一个isolation参数的,里面可以设置事务隔离级别,具体的设置方式如下:
1 |
默认就是DEFAULT值,这个就是MySQL默认支持什么隔离级别就是什么隔离级别,MySQL默认是RR级别,自然你开发的业务系统的事务也都是RR级别的了。
7.7 理解MVCC机制的前奏,undo log版本链是个什么东西
MySQL默认的RR隔离级别可以避免脏写、脏读、不可重复读、幻读,他是怎么做到的呢?
这就是由经典的MVCC多版本并发控制机制做到的,在了解MVCC机制之前,还是要先了解下undo log版本链。
简单来说,我们每条数据其实都有两个隐藏字段,一个是trx_id,一个是roll_pointer,这个trx_id就是最近一次更新这条数据的事务id,roll_pointer就是指向了更新这个事务之前生成的undo log。
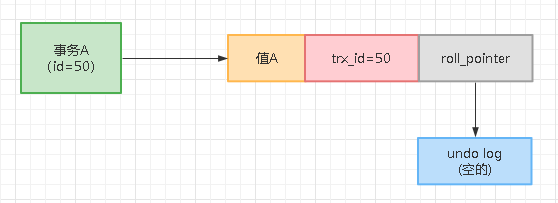
假设现在有一个事务A(id=50),插入了一条数据,那么此时这条数据的隐藏字段以及指向的undo log如下图所示,插入的这奥数据的值是值A,因为事务A的id是50, 所以这条数据的trx_id就是50,roll_pointer指向一个空的undo log,因为之前这条数据是没有的。
接着假设有一个事务B跑来修改了一下这条数据,把值改成了值B,事务B的id是58,那么此时更新之前会生成一个undo log记录之前的值,然后roll_pointer指向这个实际的undo log回滚日志,如下图所示:
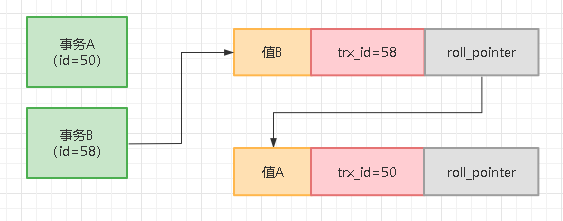
事务B修改了值为值B,此时表里的那行数据的值就是值B了,那行数据的trx_id就是事务B的id,也就是58,roll_pointer指向了undo log,这个undo log就记录了事务B更新之前的那条数据的值。
所以上图中可以看到,roll_pointer指向的那个undo log,里面的值是值A,trx_id是50,因为undo log里记录的这个值是事务A插入的,所以这个undo log的trx_id就是50。
接着假设事务C又来修改了一下这个值为值C,他的事务id是69,此时会把数据行里的trx_id改成69,然后生成一条undo log,记录之前事务B修改的那个值,此时如下图所示:
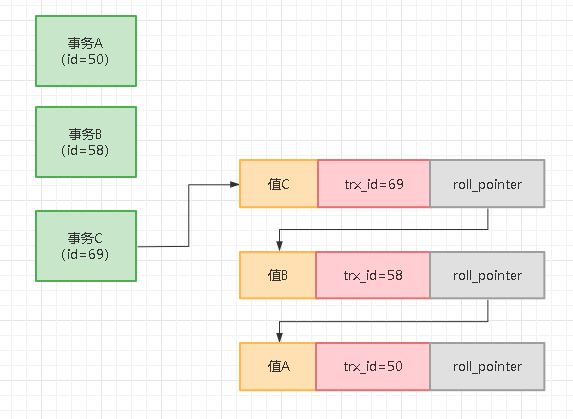
我们在上图中可以看到,数据行里的值变成了值C,trx_id是事务C的id,也就是69,然后roll_pointer指向了本次修改之前生成的undo log,也就是记录了事务B修改的那个值,包括事务B的id,同时事务B修改的那个undo log还串联了最早事务A插入的那个undo log,如图所示,过程很清晰明了。
所以多个事务串行执行的时候,每个人修改了一行数据,都会更新隐藏的trx_id和roll_pointer,同时之前多个数据快照对应的undo log,会通过roll_pointer指针串联起来,形成一个重要的版本链。
【MySQL】八、MySQL的事务(二)